Wikidata crawling
Sun 26 April 2020

Graph database representation (Photo credit: Wikipedia)
I wish to have reliable data about vehicles. I decided to rely on one large source, namely Wikipedia. I chose it because it is reviewable and most of the time reviewed, and regularly updated and completed.
Wikipedia - Wikidata relationship
Wikidata items are made to designate one entity and its relationship to other entities. One entity can is directly link to one or more Wikipedia pages, one per language.
The link Wikipedia \(\to\) Wikidata is assured via a hyperlink named "Wikidata item" in english, and the link Wikidata \(\to\) Wikipedia is present into a box named "Wikipedia".
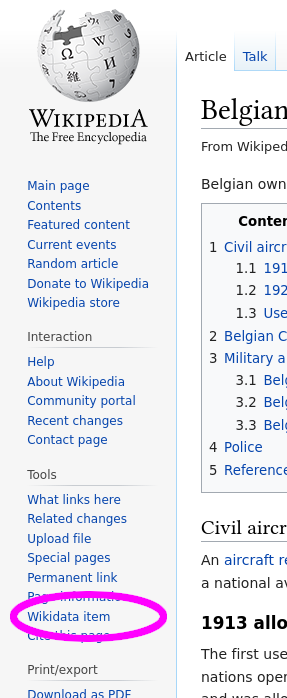
Wikipedia to Wikidata link
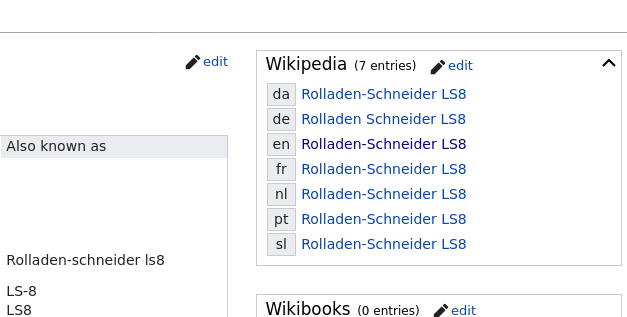
Wikidata to Wikipedia link
Wikipedia data
Characteristics are mainly put in tables. I decided to retrieve them using classic crawling technics with BeautifulSoup.
def table_to_dict(table):
"""
Args:
table (bs4.element.tag): html table tag
Returns:
(dict)
"""
res = {}
excluded_table = ("navbox", "navbox-inner", "navbox-subgroup")
if any(word in table.attrs.get("class", [""]) for word in excluded_table):
return res
for row in table.find_all("tr"):
prop = row.find("th")
value = row.find("td")
if prop and value:
res[prop.text.strip()] = value.text.strip().replace("\xa0", " ")
for row in table.find_all("tr"):
try:
prop, value = row.find_all("td")
except ValueError:
# not the right number of <td>
continue
prop = prop.text.strip().strip(":")
value = value.text.strip().replace("\xa0", " ")
res[prop] = value
return res
def html_to_props(content):
"""
Args:
content (str): html
Returns:
(dict)
"""
res = {}
soup = BeautifulSoup(content)
for table in soup.find_all("table"):
res.update(table_to_dict(table))
return res
def get_wikipedia_props(url):
"""Retrieve characteristic tables from wikipedia pages
Args:
url (str): url
Returns:
(dict)
"""
req = requests.get(url)
return html_to_props(req.content)
>>> get_wikipedia_props("https://fr.wikipedia.org/wiki/Hermione_(1779)")
{'Autres noms': '« La frégate de la liberté »',
'Type': 'Frégate de 12',
'Classe': 'Concorde',
'Fonction': 'Navire de guerre',
'Gréement': 'Trois-mâts carré',
'Architecte': 'Henri Chevillard',
'Chantier naval': 'Arsenal de Rochefort',
'Fabrication': 'Coque en chêne',
'Lancement': '1779 (coule en 1793)',
'Équipage': '255 à 316 marins',
'Longueur': '66 m (mât de pavillon compris)',
'Longueur de coque': '44,20 m',
'Maître-bau': '11,5 mètres (11,24 ?)',
"Tirant d'eau": '4,94 m (5,78 ?)',
"Tirant d'air": '46,9 m',
'Déplacement': '1 166 tonnes à vide',
'Hauteur de mât': '56,5 m (grand mât)35 m (artimon)',
'Voilure': '2 200 à 3 315 m2',
'Vitesse': '14,5 nœuds (27 km/h)',
'Armement': '26 canons de 12 livres 8 canons de 6 livres',
'Armateur': 'Marine française',
'Pavillon': 'Marine royale française Marine de la République'}
Those characteristics are often available in multiple languages, requiring post processing to improve uniformity.
Wikidata structure
Wikidata is a graph database linked to Wikipedia. Each entity is identified by a "Q number", an ID beginning with the "Q" letter followed by a variable number of digits. This graph is oriented with relationship being themselves objects (e.g. "member of" is the item Q379825).
Wikidata exploration
I created the following function to get a JSON representation of an item.
from collections import defaultdict
import requests
def get_item(ref):
"""get widikada item
Args:
ref (str): wikidata item reference
Returns:
(dict): json
"""
base_url = "https://query.wikidata.org/sparql?query="
query="""SELECT DISTINCT ?p ?property_label ?value
WHERE {{
wd:{} ?p ?value .
?property wikibase:directClaim ?p ;
rdfs:label ?property_label .
FILTER(LANG(?property_label)="en")
}}""".format(ref)
headers = {"Accept": "application/json"}
req = requests.get(base_url + query + "&format = JSON", headers=headers)
return req.json()
def wikidata_to_dict(item):
"""wikidata item
Args:
item (str): json output from get_item
Returns:
(dict): comprehensive dictionary
"""
result = defaultdict(list)
for prop in item["results"]["bindings"]:
label = prop["property_label"]["value"]
value = prop["value"]["value"]
if prop["value"]["type"] == "uri":
value = value.split('/')[-1]
result[label].append(value)
return result
>>> wikidata_to_dict(get_item("Q498614"))
defaultdict(list,
{'image': ['Combatlouisbourg400%20004210900%201924%2014072007.jpg'],
'instance of': ['Q11446'],
'country': ['Q142'],
'named after': ['Q658523'],
'Freebase ID': ['/m/04jf4sf'],
'inception': ['1779-01-01T00:00:00Z'],
'Encyclopædia Universalis ID': ['hermione-fregate'],
'derivative work': ['Q5502184'],
'Commons category': ['Hermione (ship, 1779)']})>
I used lists as characteristics can be mutlievaluated. This request gives numerical characteristics such as beam and draft for boats.
Retrieve item ID belonging to a specific category
Code speaks by itself:
import requests
def get_membership(ref, prop="P31"):
base_url = "https://query.wikidata.org/sparql?query="
query = """SELECT ?item
WHERE
{{
?item wdt:{} wd:{}.
}}
""".format(
prop, ref
)
headers = {"Accept": "application/json"}
req = requests.get(base_url + query + "&format = JSON", headers=headers)
res = req.json()
for member in res["results"]["bindings"]:
url = member["item"]["value"]
yield url.split("/")[-1]
I decided to retrieve id from URL.
Relationship Wikidata - Wikipedia
Wikidata to Wikipedia
To get Wikipedia page URLs, I coded the following function using BeautifulSoup.
from bs4 import BeautifulSoup
from bs4.element import Tag
def wikidatapage_to_wikipedialinks(item):
"""
Args:
item (str): ref
Yields:
(str): url
"""
req = requests.get("https://www.wikidata.org/wiki/{}".format(item))
soup = BeautifulSoup(req.content)
for tag in soup.find_all("div"):
if "wikibase-sitelinklistview" not in tag.attrs.get("class", ""):
continue
for href in tag.find_all("a"):
url = href.attrs["href"]
if "wikipedia.org" in url:
yield url
Wikipedia to Wikidata
Here again, I used BeatifulSoup.
def wikipedia_to_wikidata(url):
"""Retrieve wikidata item number
Args:
url (string): wikipedia url
Returns:
(string): reference
"""
req = requests.get(url)
soup = BeautifulSoup(req.content)
wikilink = next(
li
for li in soup.find_all("li")
if "id" in li.attrs and li.attrs["id"] == "t-wikibase"
)
tag = wikilink.find("a")
try:
return tag.attrs["href"].split("/")[-1]
except IndexError:
return ""
>>> wikipedia_to_wikidata("https://en.wikipedia.org/wiki/French_frigate_Hermione_(2014)")
'Q5502184'
Put it all together
From a Q item ID, if we try to get all properties, we end with:
def get_all_props(ref):
"""
Args:
ref (str): Q number
Returns:
(dict): all properties
"""
res = wikidata_to_dict(get_item(ref))
wikipedia_urls = wikidatapage_to_wikipedialinks(ref)
for url in wikipedia_urls:
res.update(get_wikipedia_props(url))
return res
Be careful, some properties are lists (those coming from Wikidata), other are strings (those coming from Wikipedia).
Mass crawling
Let's start with an iterable of Q items IDs. I'll put them into a set to
assure unicity but any iterable is OK. I won't go in details into the retrieving
of those IDs, but you may imagine the function get_membership() defined
earlier is useful.
qitems = {
"Q877343",
"Q3079847",
"Q3445980",
"Q3017039",
"Q16222749",
"Q3153932",
}
Wikidata limits the query rate, and is the list of items is long monitoring is desirable.
from datetime import datetime
from time import sleep
all_results = {}
for i, ref in enumerate(qitems):
if ref in all_results:
# speedup restarts if all_results is partially filled
continue
try_nb = 0
while try_nb < 10 and ref not in all_results:
try:
all_results[ref] = get_all_props(ref)
except: # excpetion should be specified
now = datetime.now().isoformat()
print("{} WARNING item {} (try {}/10)".format(now, ref, try_nb))
try_nb += 1
sleep(60 * try_nb)
if i % 100 == 0:
now = datetime.now().isoformat()
print("{} STATUS: item {} / {}".format(now, i, len(boat_refs)))
The result is a python dict that can easily be serialized into a JSON.
Related articles (or not):